This blog entry is my explanation to my code uploaded on my GitHub account. The link for the code for this article is Link to Matrix Multiplication Folder.
Note: I am explaning how I speed up the code and not the Matrix Multiplication Algorithms.
Please read about Matrix Multiplication algorithms here!
The configuration of the system used to run the codes were as follows : 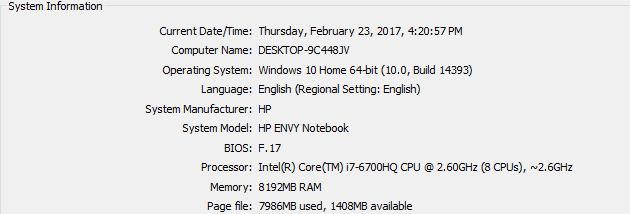
The notion of parallelism rhymes well with the notation of Divide and Conquer Approach for Algorithms provided each sub-part/task in the corresponding Divide and Conquer Algorithm have no shared data which could possible cause race conditions.
First I would like to compare the running times of all the implemented algorithms and then go on to explain how I speed up the non-parallel implementations.
Running Times for these algorithms:
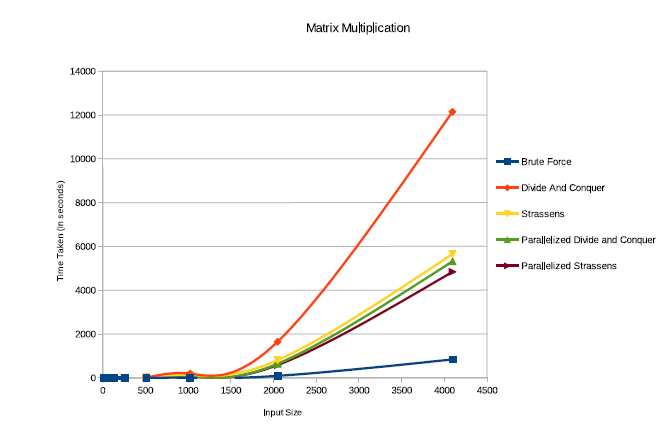
As we can see, the winner of this race is Brute Force followed by Parallel Strassen’s Matrix Multiplication algorithm closely followed by Parallel Divide and Conquer Matrix Multiplication and Strassen’s Matrix Multiplication (in the specified order). Divide and Conquer Matrix Multiplication Algorithm came last taking over 3 plus hours on the specifications specified.
Orders Of the Algorithms Used:
Brute Force Algorithm: θ(n3)
Divide and Conquer Algorithm: θ(n3)
Strassen’s Algorithm: θ(n2.80)
So why did Brute Force Come on top?
The justification I came up with was that there are lesser memory checks in the Brute Force implementation of Matrix Multiplication than that of others. Furthermore, perhaps, as in the two Divide and Conquer Algorithm, each time the 2d array is divided into subparts, the Java JVM does memory checks and Java References are pass by value add overhead.
Implementation:
Libraries Used:
import java.util.*;
import java.text.DecimalFormat;
import java.util.concurrent.*;
The java.util.* library contains all the basic utilities such as Scanner Class, System Class, Maps, Queues, etc. Read more about this library here.
The java.text.DecimalFormat library was used to round the value of time with the precision of 6 decimal digits. Read more about this library here.
The java.util.concurrent.* library contains the basic utilities for concurrent programming. Read more about this library here.
Code Explanation:
For Parallel Divide and Conquer Algorithm:
Note: As posting the full code here would make the blog article really big, I am only posting the snippets of my code here. Please refer to the folder or click on this link specified before for the full code.
Assuming that most of us know how to create a class, write the main method, create a 2d array and taking input through scanner object. I will explain few non-trivial parts of my code.
In class Parallel Matrix Multiplication:
private static final int POOL_SIZE = Runtime.getRuntime().availableProcessors();
private final ExecutorService exec = Executors.newFixedThreadPool(POOL_SIZE);
The java.lang.Runtime class allows the application to interface with the environment in which the application is running. This class has a method called availableProcessors() which returns the number of processors available to the Java virtual machine.
The newFixedThreadPool(int numberOfthreads) method of the class Executors creates a thread pool that reuses a fixed number of threads operating off a shared unbounded queue. At most numberOfthreads will actively process tasks. The ExecutorService interface allows asynchronous execution of tasks in the background.
public void multiply()
{
Future f = exec.submit(new Multiplier(a, b, c, 0, 0, 0, 0, 0, 0, a.length));
try
{
f.get();
exec.shutdown();
} catch (Exception e)
{
System.out.println(e);
}
}
The submit(Callable task) of the ExecutorService interface takes a task for execution and return a Future reference which represents the pending results of the task.
The get() method of the Future interface waits until the task is completed. It throws an InterrupedException or an ExecutionException which needs to be handled.
Let me now explain about my inner class Multiplier:
Note: As this class is a little large, it better to open this link for a better read.
class Multiplier implements Runnable
{
private double[][] a;
private double[][] b;
private double[][] c;
private int a_i, a_j, b_i, b_j, c_i, c_j, size;
Multiplier(double[][] a, double[][] b, double[][] c, int a_i, int a_j, int b_i, int b_j, int c_i, int c_j, int size)
{
this.a = a;
this.b = b;
this.c = c;
this.a_i = a_i;
this.a_j = a_j;
this.b_i = b_i;
this.b_j = b_j;
this.c_i = c_i;
this.c_j = c_j;
this.size = size;
}
public void multiply(double[][] a, double[][] b, double[][] c, int a_i, int a_j, int b_i, int b_j, int c_i, int c_j, int size)
{
if(size==1)
{
c[c_i][c_j]+=a[a_i][a_j]*b[b_i][b_j];
}
else
{
int m=size/2;
double a11[][]=copy(a,a_i,a_i+m,a_j,a_j+m);
double a12[][]=copy(a,a_i,a_i+m,a_j+m,a_j+size);
double a21[][]=copy(a,a_i+m,a_i+size,a_j,a_j+m);
double a22[][]=copy(a,a_i+m,a_i+size,a_j+m,a_j+size);
double b11[][]=copy(b,b_i,b_i+m,b_j,b_j+m);
double b12[][]=copy(b,b_i,b_i+m,b_j+m,b_j+size);
double b21[][]=copy(b,b_i+m,b_i+size,b_j+0,b_j+m);
double b22[][]=copy(b,b_i+m,b_i+size,b_j+m,b_j+size);
double x1[][]=new double[m][m];
double x2[][]=new double[m][m];
double x3[][]=new double[m][m];
double x4[][]=new double[m][m];
double x5[][]=new double[m][m];
double x6[][]=new double[m][m];
double x7[][]=new double[m][m];
double x8[][]=new double[m][m];
multiply(a11,b11,x1,0,0,0,0,0,0,m);
multiply(a12,b21,x2,0,0,0,0,0,0,m);
multiply(a11,b12,x3,0,0,0,0,0,0,m);
multiply(a12,b22,x4,0,0,0,0,0,0,m);
multiply(a21,b11,x5,0,0,0,0,0,0,m);
multiply(a22,b21,x6,0,0,0,0,0,0,m);
multiply(a21,b12,x7,0,0,0,0,0,0,m);
multiply(a22,b22,x8,0,0,0,0,0,0,m);
combine(c,add(x1,x2,m),add(x3,x4,m),add(x5,x6,m),add(x7,x8,m),c_i,c_j,size);
}
}
public void combine(double c[][],double c11[][],double c12[][],double c21[][],double c22[][],int c_i,int c_j,int n)
{
int m=n/2;
for(int i=0;i<m;i++)
{
for(int j=0;j<m;j++)
{
c[c_i+i][c_j+j]+=c11[i][j];
}
}
for(int i=0;i<m;i++)
{
for(int j=m;j<2*m;j++)
{
c[c_i+i][c_j+j]+=c12[i][j-m];
}
}
for(int i=m;i<2*m;i++)
{
for(int j=0;j<m;j++)
{
c[c_i+i][c_j+j]+=c21[i-m][j];
}
}
for(int i=m;i<2*m;i++)
{
for(int j=m;j<2*m;j++)
{
c[c_i+i][c_j+j]+=c22[i-m][j-m];
}
}
}
public double[][] add(double a[][],double b[][],int n)
{
double c[][]=new double[n][n];
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
c[i][j]=a[i][j]+b[i][j];
}
}
return c;
}
public double[][] copy(double [][]a,int n1,int n2,int m1,int m2 )
{
double c[][]=new double[n2-n1][m2-m1];
for(int i=n1;i<n2;i++)
{
for(int j=m1;j<m2;j++)
{
c[i-n1][j-m1]=a[i][j];
}
}
return c;
}
public void run()
{
int h = size/2;
if (size <= 64)
{
multiply(a,b,c,a_i,a_j,b_i,b_j,c_i,c_j,size);
}
else
{
Multiplier[] tasks = {
new Multiplier(a, b, c, a_i, a_j, b_i, b_j, c_i, c_j, h),
new Multiplier(a, b, c, a_i, a_j+h, b_i+h, b_j, c_i, c_j, h),
new Multiplier(a, b, c, a_i, a_j, b_i, b_j+h, c_i, c_j+h, h),
new Multiplier(a, b, c, a_i, a_j+h, b_i+h, b_j+h, c_i, c_j+h, h),
new Multiplier(a, b, c, a_i+h, a_j, b_i, b_j, c_i+h, c_j, h),
new Multiplier(a, b, c, a_i+h, a_j+h, b_i+h, b_j, c_i+h, c_j, h),
new Multiplier(a, b, c, a_i+h, a_j, b_i, b_j+h, c_i+h, c_j+h, h),
new Multiplier(a, b, c, a_i+h, a_j+h, b_i+h, b_j+h, c_i+h, c_j+h, h)
};
FutureTask[] fs = new FutureTask[tasks.length/2];
for (int i = 0; i < tasks.length; i+=2)
{
fs[i/2] = new FutureTask(new Sequentializer(tasks[i], tasks[i+1]), null);
exec.execute(fs[i/2]);
}
for (int i = 0; i < fs.length; ++i)
{
fs[i].run();
}
try
{
for (int i = 0; i < fs.length; ++i)
{
fs[i].get();
}
}
catch (Exception e)
{
System.out.println(e);
}
}
}
}
Continue reading “Matrix Multiplication – Using Java”

